
Serialization and Deserialization in Data Engineering
The Role of Serialization and Deserialization in Data Engineering

Today, let's get into serialization and deserialization. As we unpack these concepts, we’ll delve into real-world applications and the pivotal role they play in ensuring seamless communication between disparate systems and languages. 🚀
Understanding Serialization and Deserialization
Role of Serialization in Data Engineering
Serialization offers a way to process data across various programming languages and platforms.
Imagine you're preparing for a journey. Just as you carefully pack your belongings into a suitcase, in the digital world, serialization is about packing data into a transportable format. This process involves converting data structures or object states into a format (like JSON, XML, etc.) that can be stored in a file or transmitted across a network.
Without serialization, transmitting data such as nested objects or arrays between different parts of a distributed system would be cumbersome and resource-intensive, potentially leading to increased latency and decreased performance.
Example
Consider a scenario where a Python service has a complex data structure, such as a list of dictionaries, representing a series of data records. Each dictionary contains various data types, including strings, integers, and boolean values.
A separate Ruby application needs to process this data. However, Ruby's data structures and syntax are different from Python's. For instance, Ruby uses nil for null values while Python uses None, and true/false boolean values are lowercase in Ruby (true, false) but capitalized in Python (True, False).
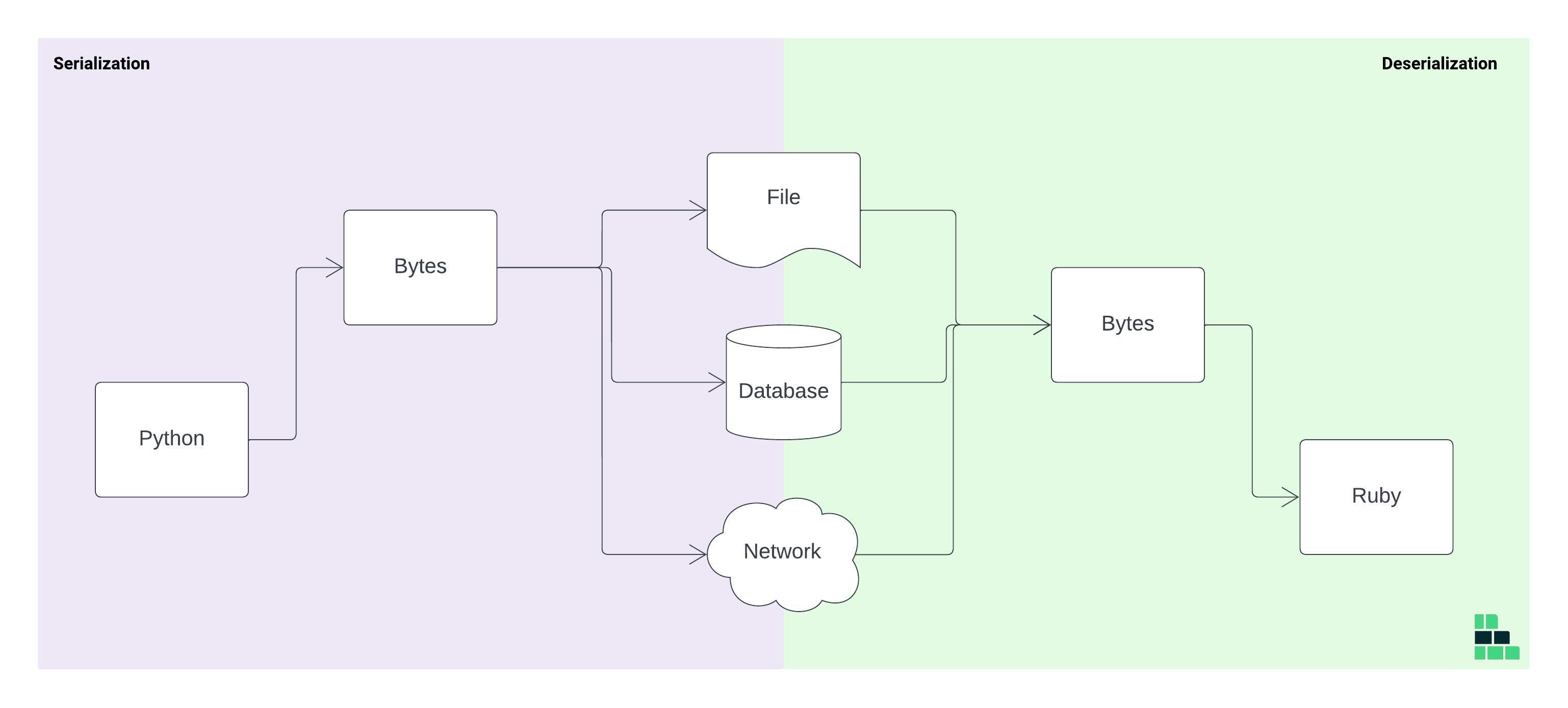
Without serialization, directly transferring this data from Python to Ruby (or any other language) would be problematic. The Ruby application would struggle to interpret Python's data structures correctly, leading to potential data loss, corruption, or errors in data processing.
Therefore, the Python service serializes its data structure into a JSON format. The Ruby application then deserializes the JSON string. Ruby’s JSON parsing library interprets the string and converts it into Ruby's native data structures, like hashes and arrays, with appropriate data types (e.g., converting true in JSON to Ruby's true).

Serialization helps bridge the gap in data type representation between Python and Ruby. By using JSON, boolean values, null values, and other data types are standardized in a way that both Python and Ruby can understand and correctly interpret upon deserialization.
Serialization provides a standardized method for data exchange between different systems and languages. It ensures that data integrity is maintained and that each system can effectively communicate and process data, regardless of the programming language used.
Deserialization
Deserialization is the process of converting the serialized data back into a usable format. It's like opening your digital suitcase and arranging your belongings (data) back into their original state, ready for use in your applications.
Serialization and Deserialization in Python
In Python, when you serialize data, you're converting it into JSON format. Deserialization is the reverse; you're converting JSON data back into Python data structures. JSON (JavaScript Object Notation) is a format that's really easy to read and write for humans and machines. It's used a lot for sending data between a server and a web application. JSON works well because it's simple and can be used with many programming languages, not just JavaScript.
Python vs. JSON: A Comparison
Here's a quick look at how Python types match up with JSON types:

Let's use Python's json module to see serialization and deserialization in action:

Serialize
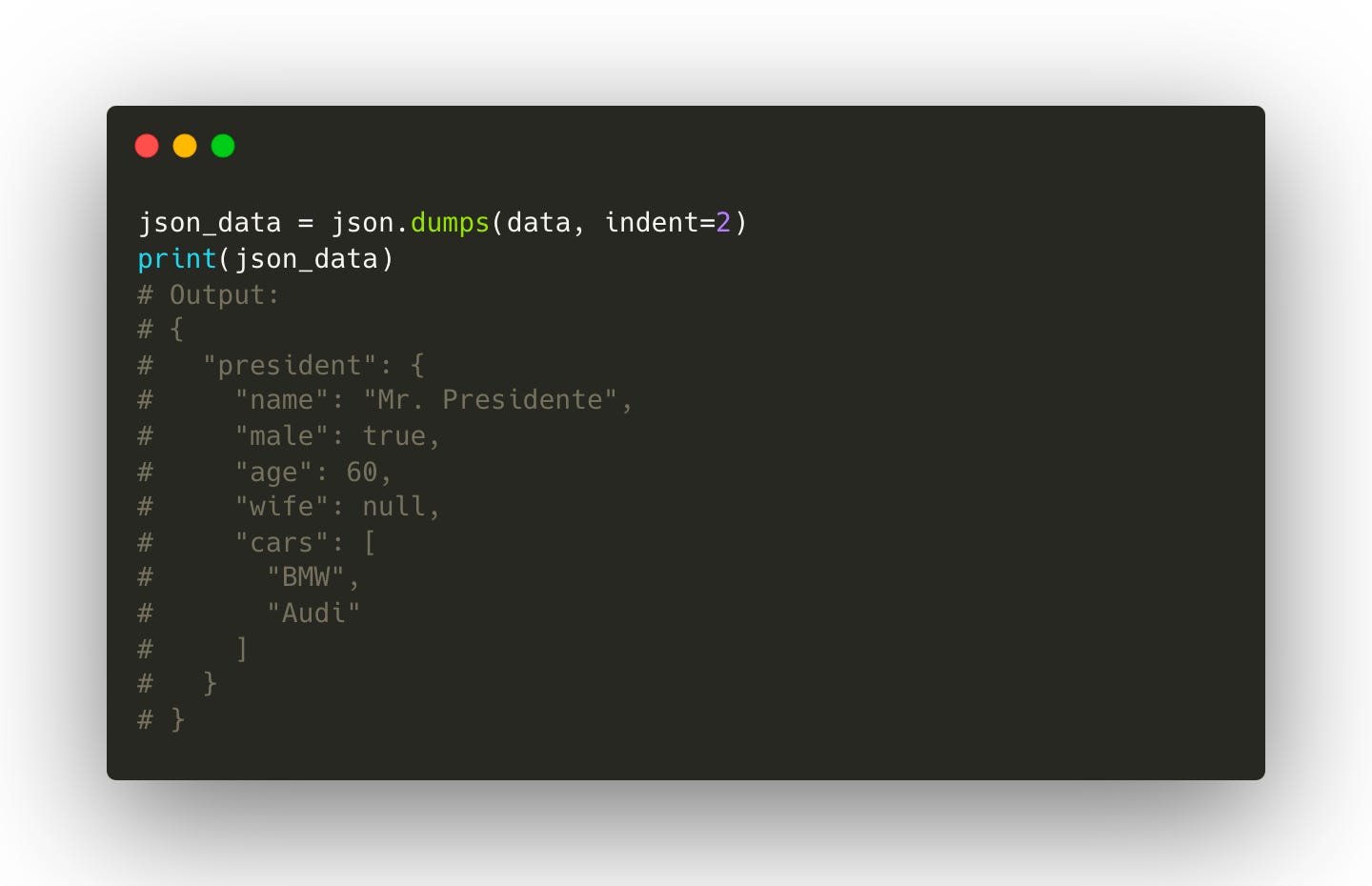
Here, json.dumps() turns the Python data into a JSON string.
While JSON is popular for its readability and simplicity, data engineers often work with several other formats:

XML and YAML: Used in configurations and data exchange where human readability is important.
Binary Formats: Such as Apache Avro or Protocol Buffers, which are more efficient in terms of size and speed, making them suitable for high-performance applications like streaming data.
The choice of serialization format can significantly impact the speed and size of data processing. Binary formats are typically faster and smaller than text-based formats like JSON, which can be crucial in large-scale data processing.
Schema Evolution
Data schemas evolve over time. Managing these changes without breaking existing systems is a critical skill in data engineering. Techniques like schema versioning and backward/forward compatibility are important for long-term data storage and evolution.
For example, here we have two versions of a schema for an "Employee" record.
Version 1 of the Schema:

This version includes two fields: name (a string) and age (an integer).
Version 2 of the Schema:

In version 2, a new field, department, is added with a default value of "General". This change reflects an evolution of the data structure - perhaps the organization grew, and now departmental data is crucial.
Serializing Data with Version 1 Schema:

Here, data conforming to the first version of the schema is serialized. This means converting the Python dictionary to a JSON string, which can be easily stored or transmitted.
Deserializing with Version 2 Schema:

When we deserialize, we use version 2 of the schema. The data originally serialized didn't have a department field, so we use setdefault to add this field with a default value if it's not present. This ensures compatibility with the newer schema version.
Backward Compatibility: The new version of the schema (version 2) can handle data encoded with the older schema (version 1). This is crucial when old data or systems are still in use.
Forward Compatibility: While not demonstrated in the example, this would mean version 1 of the schema could handle data encoded with version 2. Typically, this requires the older system to ignore or appropriately handle new fields it doesn't recognize.
Why Is This Important?
Schema evolution is fundamental in data engineering because data structures inevitably change as business requirements evolve. Managing these changes without disrupting existing systems or data pipelines is crucial for:
Ensuring that data remains accurate and consistent despite structural changes.
Older systems or datasets should continue to function correctly, even as new features or requirements emerge.
Flexible schema management allows businesses to adapt quickly to new requirements without overhauling existing data infrastructures.
Closing Thoughts
As we conclude our exploration, it’s clear that serialization and deserialization are more than just technical processes - they are the lifelines that connect various facets of the digital world. In the ever-changing landscape of data engineering, the ability to effectively manage schema evolution is not just a skill but a necessity. It enables us to embrace change, ensuring that our data infrastructures are not only robust and scalable but also flexible enough to adapt to the future’s demands.
As we continue to navigate this dynamic field, let us remember that in the world of data, change is the only constant, and our readiness to adapt is our greatest asset.