
A Deep Dive into Apache Spark Partitioning #1
Understanding and Leveraging Spark Partitions for Enhanced Data Processing

Hello everyone!👋
Welcome to our deep dive into the world of Apache Spark, where we'll be focusing on a crucial aspect: partitions and partitioning. This is a key area that, when optimized, can significantly enhance the performance of your Spark applications.
This blog post marks the beginning of a series where we will explore various facets of Apache Spark in depth. Stay tuned for more insights and advanced discussions in the follow-up series.
What are Spark Partitions?
Simply put, partitions in Spark are the smaller, manageable chunks of your big data. Imagine your data as a giant pizza – partitions are the slices that make it easier to eat (or in our case, process).
When Spark reads a dataset, be it from HDFS, a local file system, or any other data source, it splits the data into these partitions. This is where the magic begins. Each partition is processed in parallel, allowing Spark to perform computations lightning-fast. This parallelism is the heart and soul of Spark's efficiency. The way data is partitioned can have a profound impact on the performance of your Spark application.
Parallelism
Parallelism in Spark is all about doing multiple things at the same time. The core idea is to divide the data into smaller chunks (partitions), so they can be processed simultaneously. The more partitions you have, the more tasks can run in parallel, leading to faster processing times.
Imagine you have a dataset with 1 million records. If this dataset is divided into 10 partitions, Spark can launch 10 tasks to process each partition simultaneously. If the cluster has sufficient resources, these tasks will run in parallel, speeding up the process. However, if you increase the number of partitions to 100, and assuming your cluster has the resources (like CPU cores) to handle these tasks, Spark can now launch 100 tasks to run concurrently. This dramatically increases parallelism and reduces the total time taken to process the entire dataset.
The general guideline is to have partitions small enough for efficient distribution across the cluster but large enough to avoid the overhead of task scheduling and JVM garbage collection. A common practice is to aim for partitions between 100 MB and 200 MB in size.
Foundational Concepts in Apache Spark
To fully grasp shuffle and shuffle partition tuning later down, it’s crucial to understand the core concepts of transformations within Spark's framework. Transformations are essentially the operations that process data within Spark's “Resilient Distributed Datasets (RDDs)” (don’t worry about RDDs too much). In Spark, these transformations are classified into two primary types: narrow transformations and wide transformations.
Narrow Transformations
Narrow transformations are specific types of operations where each piece of the input data contributes to only one part of the output. Picture this as a one-to-one relationship where every item in your input data (residing in a partition) maps directly to a single output partition. In more technical terms, the data required to process the records in one partition of the resulting RDD comes from at most one partition of the parent RDD.
Some common examples of narrow transformations include:
Map Transformation: This is like applying a specific recipe to each ingredient in your dish. In Spark, map() takes each element in the RDD and applies a function to it, producing a new RDD as the result.
Filter Transformation: Imagine sieving through your ingredients to pick only the ones that meet certain criteria. The filter() function in Spark does something similar. It returns a new RDD containing only those elements that satisfy a specified condition.
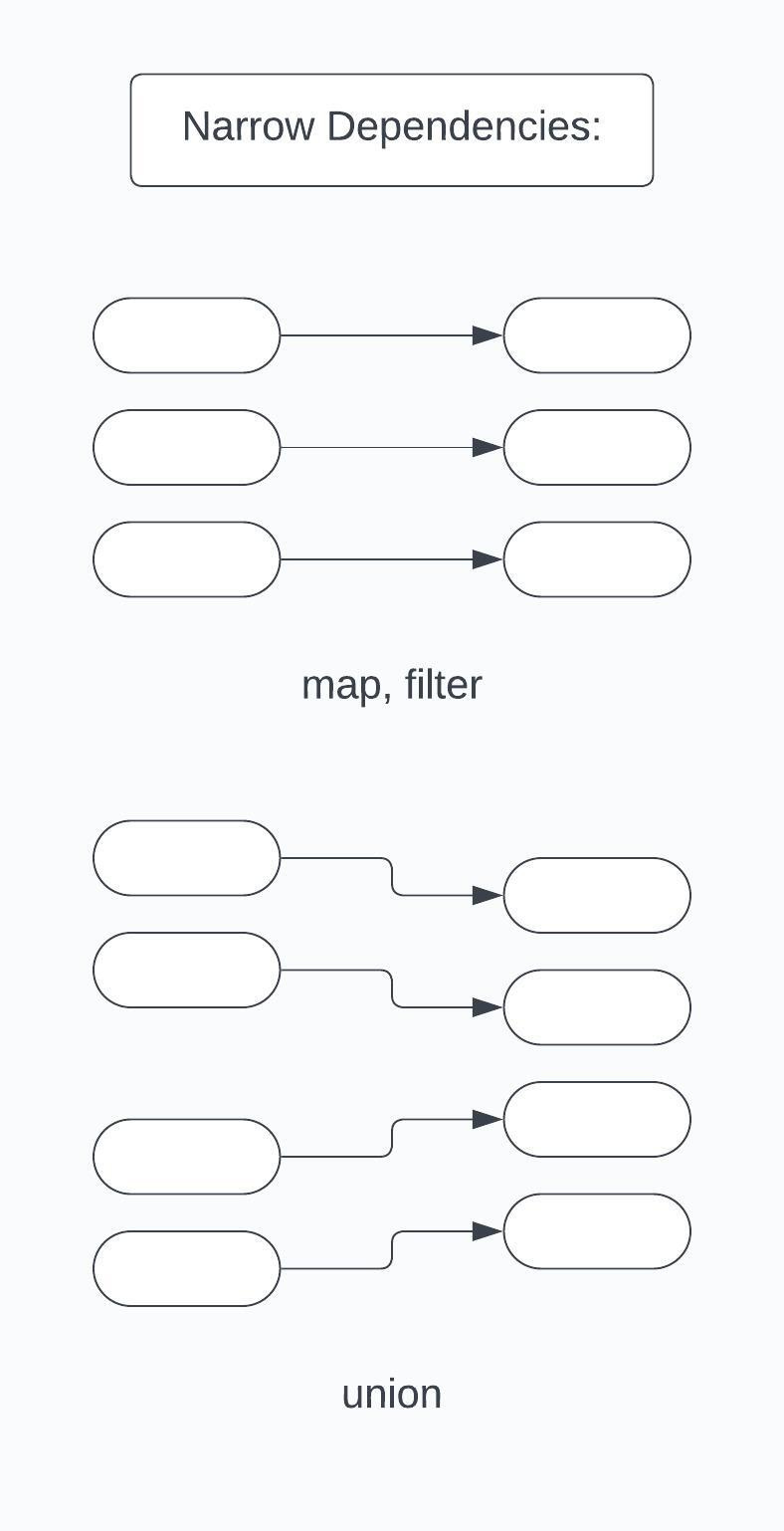
The hallmark of narrow transformations is that they do not require shuffling of data across different partitions. This makes them highly efficient, as each partition can be processed independently and locally without needing to communicate with others.
Wide Transformations
In contrast, wide transformations are operations where the input data from multiple partitions contribute to a single partition in the output. This can be likened to a scenario where ingredients from different sections of your pantry are mixed together into a single dish. During wide transformations, data is shuffled and redistributed across various partitions and potentially across different nodes in a cluster. This shuffle is essential because the data required to compute the records in one partition may reside across multiple partitions of the parent RDD.
Examples of wide transformations include:
GroupBy Transformation: Think of this as grouping similar items in your pantry. In Spark, groupBy() collects data based on a key and brings together the corresponding values.
ReduceByKey Transformation: This is akin to combining similar items to create a more compact arrangement. The reduceByKey() function merges the values for each key using a specific reduce function.
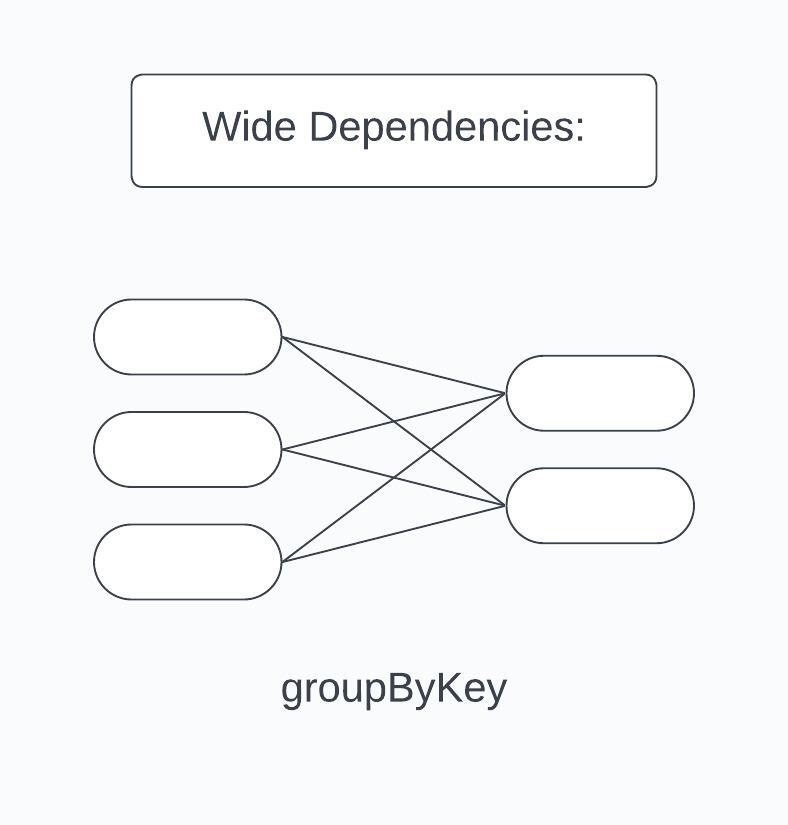
Understanding wide transformations is crucial for grasping the concept of shuffle operations in Spark. Shuffling is a process that redistributes the data across different partitions and often involves intensive operations like disk I/O, network I/O, and data serialization. It occurs typically after a wide transformation when the data needs to be reorganized across partitions. This reorganization is resource-intensive and can significantly impact the performance of Spark applications, making shuffle partition tuning a critical aspect of Spark optimization.
Spark Translates Transformations into Execution Plans
To deepen your understanding of partitioning in Apache Spark, it's pivotal to understand how Spark processes high-level transformations and actions into execution plans. This process involves two key stages: the formation of logical and physical plans. These plans are crucial as they illustrate how Spark internally handles the transformations and actions you write in your code, and how partitioning decisions influence these processes.

Logical Plan
The logical plan in Spark represents a high-level, abstract representation of what operations are to be performed on the data. When you write a Spark query, using transformations like map, filter, or groupBy, Spark builds a logical plan to represent these operations. This plan is akin to a blueprint; it outlines the sequence of steps required to transform the data but does not delve into the specifics of how to execute these steps.
The logical plan is an abstract representation of the computations and does not include information about how the data will be distributed across the cluster or how the computations will be physically carried out.
Spark's Catalyst optimizer analyzes this logical plan and applies various optimization rules to create an optimized logical plan. These optimizations are aimed at improving the efficiency of the query without altering its outcome.
Physical Plan
Once the logical plan is optimized, Spark converts it into a physical plan. The physical plan is a detailed roadmap of how the query will be executed in the Spark cluster. It includes specifics on how the data will be partitioned, shuffled, and aggregated across the nodes in the cluster.
The physical plan describes the exact execution strategy for the query, including which tasks will be performed on which nodes, how data will be shuffled between nodes, and how partitions will be read and processed.
Partitioning decisions directly impact the physical plan. For instance, the number and size of partitions affect how Spark decides to distribute tasks across the cluster. An optimized partitioning strategy can lead to a more efficient physical plan, reducing resource usage and improving overall query performance.
The Interplay Between Partitioning & Execution Plans
Understanding the transition from logical to physical plans is crucial when considering partitioning strategies. Effective partitioning ensures that when Spark creates the physical plan, it can do so in a way that optimizes resource utilization and query execution time. For example, if data is partitioned in a manner that aligns with the operations being performed (like partitioning by a key that will be used in a groupBy operation), Spark can execute these operations more efficiently, minimizing the need for expensive data shuffles and network I/O.
The Partitioning Playbook
So, how do we partition data effectively in Spark? Here are some strategies:
Hash Partitioning
This is the default partitioning method in Spark. Data is distributed based on a hash function of the key, ensuring even distribution (in most cases). It's particularly effective when you don't have any specific requirements for data ordering or grouping. However, if some keys are more frequent (a common occurrence in real-world data), hash partitioning can lead to uneven data distribution, known as data skew. In such cases, you might need to consider alternate partitioning strategies.
Range Partitioning
Range partitioning is about dividing data based on key ranges, ensuring that each partition contains a specific range of data. Here, keys are sorted, and ranges are defined so that each partition gets a contiguous range of keys. For example, in a dataset of customer records, one partition might hold records with customer IDs from 1 to 1000, the next from 1001 to 2000, and so on. This method is ideal for operations that require sorted data, such as certain types of joins or when you're preparing data for window functions. It's also useful for mitigating data skew with keys that have a non-uniform distribution.
Custom Partitioning
Sometimes, the default methods don't cut it. In such cases, you can create your custom partitioner. It's more complex than the default methods but can offer significant performance improvements when done right.
Adjusting Partitions Dynamically
We can adjust the number of partitions by using transformations like repartition() or coalesce().
Use repartition() to increase the number of partitions, which can be beneficial when you need more parallelism or when the data is unevenly distributed post-transformation.
Use coalesce() to reduce the number of partitions, which is useful to avoid shuffling and improve performance, especially after filtering down a large dataset.
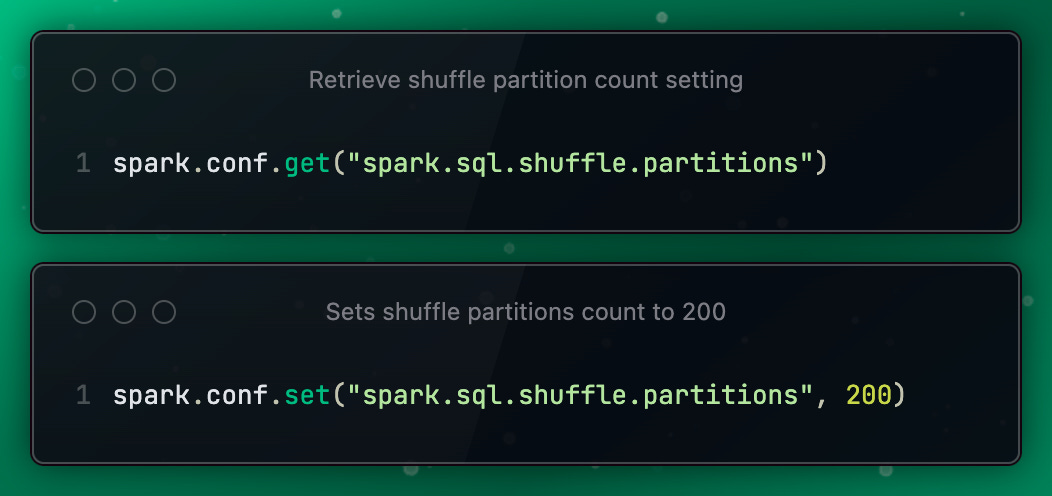
In Apache Spark, the spark.sql.shuffle.partitions configuration parameter plays a critical role in determining how data is shuffled across the cluster, particularly in SQL operations and DataFrame transformations. By default, this parameter is set to 200. Understanding the rationale behind this default setting and its impact on parallelism and resource utilization is key to optimizing Spark applications.
When a Spark operation requires data to be shuffled (like a join, groupBy, or aggregations), the data is redistributed across the cluster. The spark.sql.shuffle.partitions setting defines the number of partitions that are used for this shuffle operation.
Partitioning Considerations
While partitioning can significantly boost performance, it's not a "set and forget" deal. Too many small partitions can increase scheduling overhead, while too few large partitions can reduce parallelism.
Find that Goldilocks zone :).
We use Spark's UI to monitor task times and shuffle read/write times. This will give you insights into whether you need to repartition your data. Settings like spark.sql.shuffle.partitions and spark.default.parallelism are your friends. Tweak them based on your data and cluster size.
To navigate this delicate balance, it's essential to leverage the monitoring tools at your disposal. Spark's UI is a valuable resource for observing task times and shuffle read/write metrics. This data provides crucial insights, helping you determine whether your current partitioning strategy is effective or if adjustments are needed. For instance, unusually long task times or excessive shuffle operations can signal a need for repartitioning.

Source: https://spark.apache.org/docs/3.0.0-preview2/web-ui.html
When it comes to dealing with skewed data, techniques like salting - which involves adding random noise to keys - can be highly effective. This approach helps distribute the data more evenly across partitions, mitigating the delays and inefficiencies caused by skewness.
Also, consider both the size of your data and the specifics of your cluster when deciding on the number of partitions. A general rule of thumb is to aim for 2-3 tasks per CPU core available in your cluster. This helps ensure that the workload is evenly distributed across the cluster, maximizing resource utilization without overwhelming any single node.
Another strategy to consider is leveraging Spark’s dynamic resource allocation feature. This capability allows Spark to adjust the number of executors for a job dynamically, based on the workload. Such flexibility is particularly useful for handling varying data sizes efficiently, ensuring that resources are allocated where and when they are needed most.
In cases where your application frequently interacts with persistent storage, optimizing data storage format and partitioning can have a significant impact on performance. For example, using columnar storage formats like Parquet and appropriately partitioning data on disk can expedite read/write operations. This optimization is especially critical for I/O-intensive applications and can lead to noticeable improvements in processing speed.
Adaptive Query Execution (AQE)
In Databricks, a significant feature that enhances the efficiency of Apache Spark applications is Adaptive Query Execution (AQE). Enabled by default from version 7.3 LTS and onwards, AQE dynamically adjusts the number of shuffle partitions during different stages of query execution. This automatic adjustment is based on the size of the map-side shuffle output. In AQE, as the size of data changes across various stages of a query, the number of shuffle partitions is automatically modified.
TPC-DS performance gains from AQE

Source: https://www.databricks.com/blog/2020/05/29/adaptive-query-execution-speeding-up-spark-sql-at-runtime.html
One of the primary benefits of this feature is its ability to automatically optimize the shuffle process by dynamically adjusting the number of partitions based on the runtime data. This leads to improved resource utilization and enhanced overall performance. In scenarios where data skew is evident, this feature automatically detects and mitigates the issue during shuffle operations, which is critical for maintaining query efficiency. Moreover, the adaptive optimization minimizes the management overhead that is usually associated with handling too many small tasks or too few large tasks, thus effectively balancing the workload. Another significant advantage is the simplification it brings to configuration management, reducing the necessity for manual tuning of spark.sql.shuffle.partitions. Often, this results in faster execution times for queries, particularly those that are complex or have variable data workloads.

Manually setting spark.sql.shuffle.partitions requires an in-depth understanding of the data distribution, which can be complex and challenging, especially for dynamic or varying workloads. Manual tuning tends to be less flexible and might not adapt well to changes in data size or distribution, potentially leading to less than optimal performance.
Understanding the Default Value of 200
The default value of 200 for spark.sql.shuffle.partitions is a middle ground intended to provide reasonable parallelism without overwhelming the cluster. It's based on the assumption that a typical Spark cluster might not be extremely large-scale. For smaller to medium-sized clusters, 200 partitions are often enough to achieve effective parallelism. If the number of partitions were set too high by default, it could lead to a large number of small tasks. These small tasks can cause excessive overhead in task scheduling and management, reducing overall efficiency. On the flip side, setting this number too low could result in too few large tasks. This can lead to insufficient utilization of the cluster resources, as fewer tasks mean less parallel processing.
Adjusting spark.sql.shuffle.partitions
Here is a sample Python code for calculating the value:
| import math | |
| import sys | |
| def calculateShufflePartition(shuffle_size: int, num_cores: int, part_size: int): | |
| total_partitions = (shuffle_size * 1024) / part_size | |
| core_cycles_per_partition = total_partitions / num_cores | |
| recommended_shuffle_partitions = math.floor(core_cycles_per_partition) * num_cores | |
| max_partition_size_config = ( | |
| 'spark.conf.set("spark.sql.files.maxPartitionBytes", ' | |
| + str(part_size * 1024 * 1024) | |
| + ")" | |
| ) | |
| shuffle_partitions_config = ( | |
| 'spark.conf.set("spark.sql.shuffle.partitions", ' | |
| + str(recommended_shuffle_partitions) | |
| + ")" | |
| ) | |
| print("Total Partitions in Spark: " + str(total_partitions)) | |
| print("Core Cycles per Partition: " + str(core_cycles_per_partition)) | |
| print("Recommended Shuffle Partitions: " + str(recommended_shuffle_partitions)) | |
| print("\\n--Configuration Settings--") | |
| print(max_partition_size_config) | |
| print(shuffle_partitions_config) | |
| if __name__ == "__main__": | |
| shuffle_sz = int(sys.argv[1]) | |
| core_count = int(sys.argv[2]) | |
| partition_sz = int(sys.argv[3]) | |
| calculateShufflePartition(shuffle_sz, core_count, partition_sz) |
While 200 is a sensible default, it's not a one-size-fits-all number. Depending on the specific use case and the cluster's resources, adjusting this value can lead to significant performance improvements.
In a large-scale environment with a significant amount of data and a robust cluster, increasing the number of shuffle partitions beyond the default can enhance parallel processing and reduce the time taken for shuffle operations.
Conversely, in smaller environments, decreasing the number of shuffle partitions might be more effective. This can reduce the overhead of managing a large number of small tasks and make better use of the available resources.
It’s essential to monitor the performance of your Spark jobs and adjust the spark.sql.shuffle.partitions setting accordingly. Spark UI and other monitoring tools can provide insights into task durations and shuffle read/write metrics, which are helpful in determining the ideal partition count for your specific scenario.
The Impact of Partitioning in Apache Spark
To truly understand the significance of partitioning in Apache Spark, let's explore some real-world examples. These scenarios will highlight how different partitioning strategies can markedly impact the performance of specific tasks or queries.
Scenario #1:Log Data Analysis for Web Traffic
Scenario: A company analyzes its web server logs to understand traffic patterns. The logs are time-stamped and need to be processed every hour.
Without Optimized Partitioning: If the data is partitioned without considering the time element, some hours (like peak hours) have significantly larger partitions than others. This uneven partitioning results in longer processing times during peak traffic hours.
With Optimized Partitioning: Implementing a time-based partitioning strategy, where data is partitioned by the hour of the day, leads to more evenly sized partitions. This approach aligns the partitioning strategy with the inherent data distribution, enabling more consistent and faster processing across all hours.
Scenario #2: Large-Scale Sensor Data Aggregation
Scenario: A utility company aggregates data from millions of sensors across a smart grid to monitor and optimize energy distribution.
Without Optimized Partitioning: The default partitioning strategy results in a few extremely large partitions due to the higher concentration of sensors in certain areas. This causes memory issues and slows down the aggregation process.
With Optimized Partitioning: By custom partitioning the data based on geographic zones, which evenly distributes the sensor data, the company achieves better parallelism and a significant reduction in processing time. This also prevents memory overload on certain nodes, ensuring a smoother operation of their data pipeline.
Managing Resource Utilization
When it comes to Apache Spark, effective resource management is as important as the data processing itself. Let's break down how efficient partitioning leads to optimal use of your cluster's resources, such as CPU and memory, and what strategies you can adopt to maintain a balance.
Balancing Workloads Across Nodes
Imagine your Spark cluster as a team of runners in a relay race. If one runner has a much longer route than the others, the team's overall performance is impacted. Similarly, in a Spark cluster with 4 nodes, suppose you have a dataset divided into 4 large partitions. In an ideal scenario, each node processes one partition. However, if one partition is notably larger, the node handling it will take more time, hogging more CPU and memory, while the others finish early and sit idle. This is akin to one runner having a much longer track to cover. Instead of 4 large partitions, splitting the dataset into 16 smaller, evenly sized partitions means each node processes 4 smaller tasks. This results in a more evenly distributed workload, keeping all nodes actively engaged and preventing any from becoming bottlenecks. Keeping an eye on each node's workload is crucial. Use tools like Spark UI to monitor the load on each node. This helps identify any imbalances where certain nodes are overburdened or underutilized.
Closing Thoughts
In the world of Apache Spark, understanding and optimizing partitions is like knowing the secret sauce to a recipe. It can transform your data processing tasks from mundane to marvelous. Whether you're a data engineer or a data enthusiast, mastering the art of partitioning is a skill worth acquiring. So, go ahead, play around with partitions, and watch as your Spark applications soar to new heights of efficiency!
Remember, the key to mastering Apache Spark is practice, curiosity, and a bit of patience.
Happy data processing! 🚀📊